
Going Serverless: How BridgePhase harnessed serverless technologies to redesign the company website.
Topics in this article:
It's no secret that the website of an organization is the modern, digital equivalent of a flagship, store front, or banner. Web content is the cornerstone of modern brand identity. Consumers and citizens from every walk of life make first contact with and form first impressions of an organization through that organization's digital presence or lack thereof. Looking for a local service company? The search naturally beings online. Going to try a new restaurant this weekend? Better check their website for menus and reservations. Trying to decide which consulting group would be better suited for your specific business problem? Time to compare websites for relevant experience.
With this digital primacy in mind, we at BridgePhase decided to take a fresh look at the company website last year. Our goal was twofold. First, we wanted to evaluate whether or not we were clearly conveying our value proposition. Second, we wanted to determine if meaningful security, performance, or cost effectiveness improvements could be made by redesigning the website. As it turned out, we identified enough improvements to redesign the website from top to bottom including UX, content, and the underlying technologies used to build and deliver the website.
In this article we're going to dive into some technical aspects of the BridgePhase website redesign. For now, we aren't going to discuss UX or website content. We will explore UX in detail in a later article dedicated to user centered design and experience. Let's focus on the architecture of bridgephase.com and how we harnessed serverless technologies to make it happen.
Starting Point
The company website was first deployed many years ago as a Wordpress managed service offering. We selected certain aspects of the design, layout, and content but the inner workings of the website and the infrastructure that backed it were mostly an afterthought. At the time, BridgePhase only had a few employees. It made very little sense to dedicate time and energy into designing, deploying, and operating our own website in-house.
Some years later when a critical vulnerability was discovered in a specific version of Wordpress, one of our team members contacted the company that provided the managed Wordpress service upon which the BridgePhase website was hosted. We requested what we thought was something very simple - Update the version of Wordpress being used to provide the managed service. The vulnerability, as is the case with nearly all vulnerabilities, could be remediated simply by using a more recent version of Wordpress.
It turned out that, according to the company providing the managed service, upgrading to a new version of Wordpress was not an option because... reasons. We were actually never given a good reason other than being told "techincal reasons". By that point, we had as a company become proficient with all things AWS. So when the managed service company refused to budge on what was tantamount to a non-negotiable, yet seemingly simple, step to secure the BridgePhase website, we quickly made the decision to deploy and operate the Wordpress version of the website ourselves using one of our "internal" AWS accounts. The architecture of the initial bridgephase.com Wordpress deployment is shown in Figure 1 below.
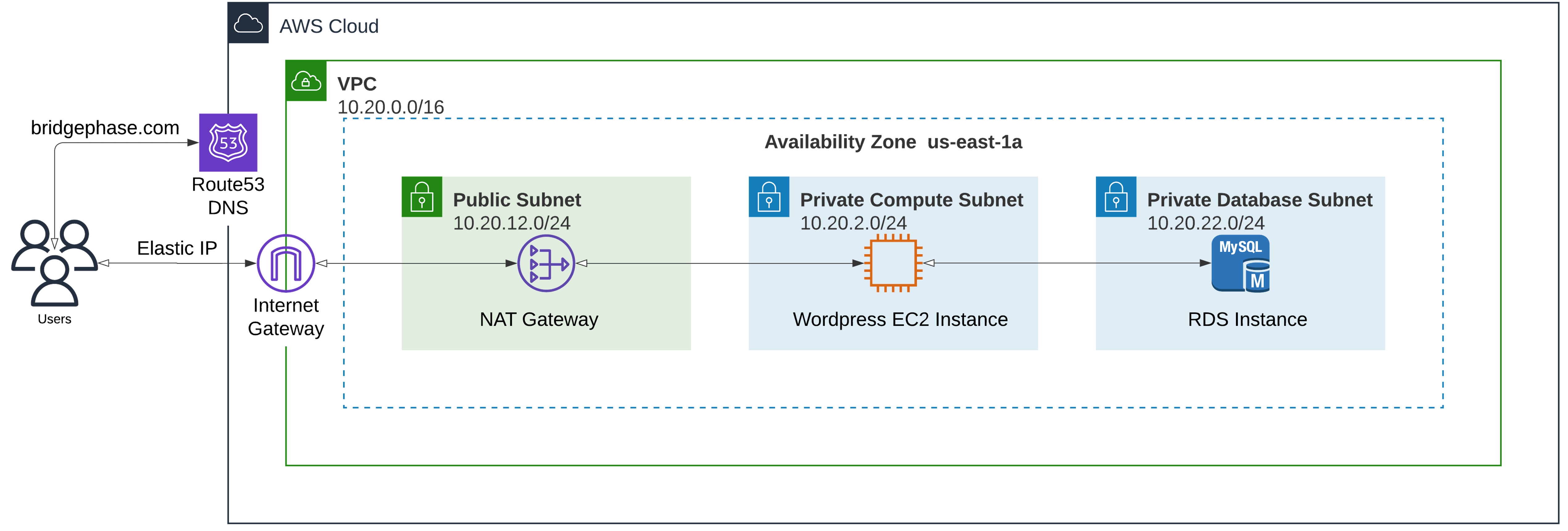
As you can probably tell, the design was as simple as it could possibly be - with the inherent advantages and disadvantages that go along with simplicity. The primary benefit of such a simple initial deployment was that we were now in complete control of our environment as the single tenant in an AWS account that we owned and administered. This allowed us to, crucially, use a more recent version of Wordpress that did not have any known vulnerabilities at the time. That flexibility was a big win but there were also some downsides to the simplistic architecture including:
- 1. Availability - We moved from a managed service offering with a known service level agreement (SLA) to a single EC2 instance connected to a single-zone RDS instance. The website availability was now the lowest common factor of the availability of AWS EC2 and RDS of one specific availability zone (us-east-1a) of one specific region (us-east-1/N.Virginia). While AWS has been consistently providing 3+ nines of availability, our deployment was clearly not an optimal example of fault tolerance.
- 2. Encryption in Transit (HTTPS/TLS) - The single EC2 instance did not have a corresponding load balancer. Without a load balancer we couldn't provision and attach an AWS managed TLS certificate through AWS Certificate Manager (ACM). Our other option was to buy a TLS certificate and add it to the Wordpress server. Since we did not want the operational burden of managing a certificate and because our website did not contain any data that needed to be encrypted over-the-wire, we opted to go for plain HTTP connections for requests targeting the Wordpress server.
- 3. Maintenance - Managed services can be the right choice for many use cases, for many teams, under many circumstances. For small teams, we almost always advocate for the use of managed services for any use case that is not directly related to the value proposition that your organization provides. One obvious exception to the recommendation to use managed services is when your security or data sovereignty requirements cannot be satisfied by the managed service or the provider of the service. In our specific scenario, the service provider was flat out unwilling to take simple steps to remediate a known, critical vulnerability. By managing the deployment ourselves we gained the flexibility that I described above at the cost of ongoing maintenance for things like Wordpress patches, data backups, OS package updates, etc.
- 4. Cost - Managed services and SaaS products can often achieve economies of scale by providing what are essentially "shared" compute, network, and storage resources. An environment in which resources are shared in this way is referred to as a multi tenant environment. SaaS providers excel at optimizing utilization of those shared resources so they can, in theory and very often in practice, provide customers with very reasonably priced subscriptions to those services. By choosing to provision and manage our own resources we were choosing to become the sole tenant and consequentially assume higher unit costs for essentially the same result - a website accessible over HTTP. We will take a closer look at these costs at the end of this article.
The initial deployment satisfied our most urgent requirement of remediating the known vulnerability. With that out of the way we were now free to focus on an end-to-end redesign of the website that would allow us to achieve the goals that we described earlier in this article. So let's do a deep dive into the redesign to see how we met our goals by going serverless!
Redesign
The first step in our redesign journey was to clearly establish our goals and objectives. Hopefully, anyone out there embarking on a new analysis or initiative starts with this step. We've all been in one of those meetings or calls in which "innovative" solutions were being tossed around, evangelized, and sometimes even agreed upon before the problem or objectives were even defined. To avoid that we started with the following objectives:
- Security - All website traffic should be encrypted in transit via HTTPS with a specific TLS minimum protocol version enforced.
- Availability - The website should continue to be accessible in the event that any single AWS availability zone has an outage or is otherwise unavailable. The website should be available, as defined by the percentage of requests to the website processed successfully, 99.9% of the time.
- Performance - The overall PageSpeed performance for the website should have a performance score of at least 85. This level of performance should be consistent throughout the continental United States.
- Maintenance & Operations - The number of operational tasks including patches, updates, and configuration management steps should be minimized. Ideally, the only ongoing maintenance should be updating the website content itself.
- Cost - Reduce website cloud spend by at least 25% compared to the initial deployment described above.
- Open Source - Use only open source tools and frameworks to develop and deploy the website. Except for the underlying infrastructure, proprietary or "closed" frameworks and platforms like Wordpress should not be used.
With those objectives solidified, we started to evaluate various alternatives for building, deploying, and operating the website. One of our first key insights was that there was absolutely no reason the website needed to have a backend. The entire website could be bundled and delivered as static resources (HTML, CSS, Javascript, images, etc.). We realized that deploying the website as static content inherently lends itself to the use of a content delivery network (CDN) which would go a long way to accomplishing many of the objectives that we outlined above.
Enter Serverless
As an AWS Partner for several years, we already had extensive experience deploying and operating static content through the use of Amazon's exceptional CDN - CloudFront. CloudFront delivers static content through a global network of fiber ("backbone network") and content caches, referred to as "edge locations" and "regional caches", as illustrated in Figure 2 below.
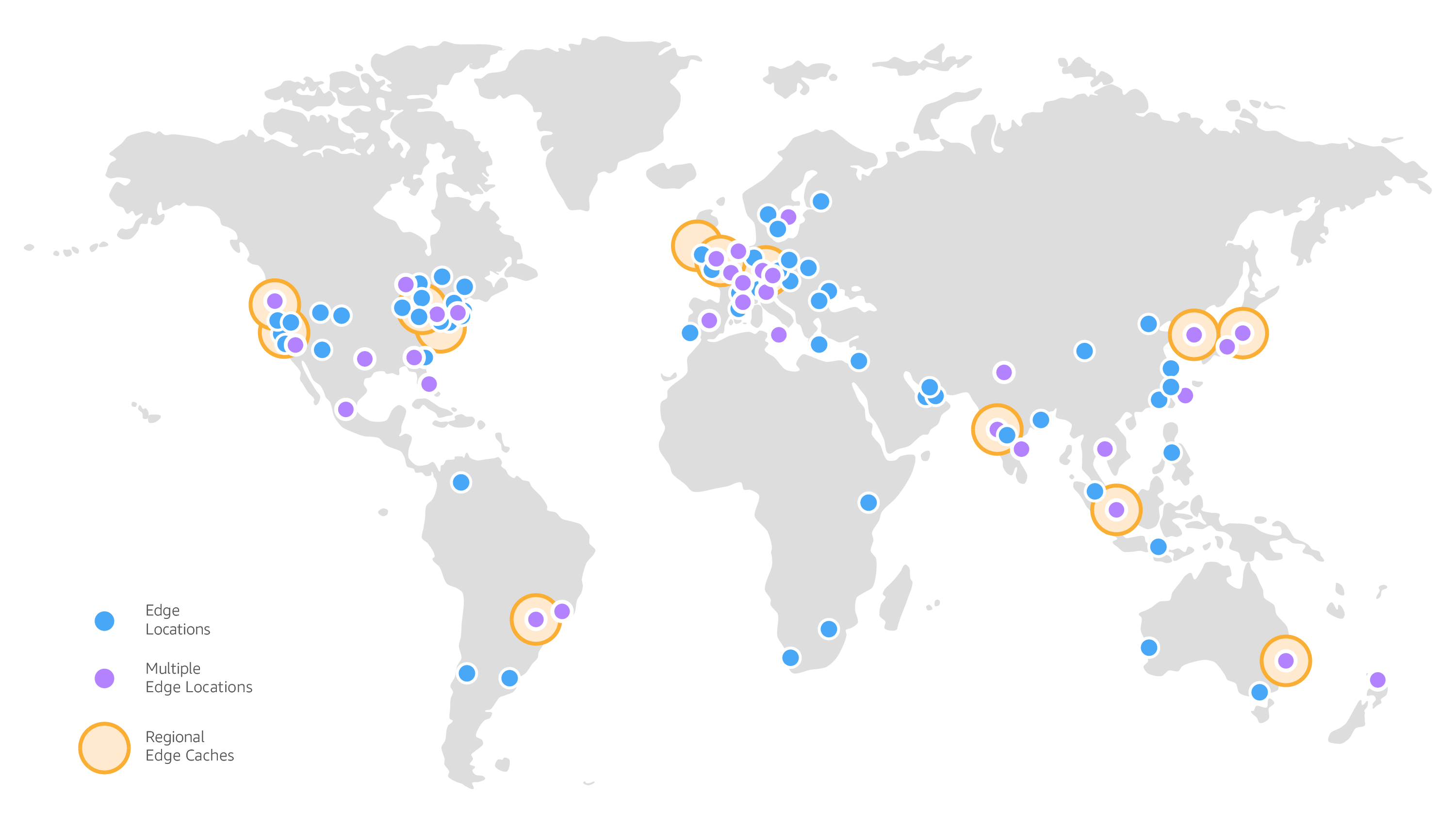
There are numerous technical, operational, and financial benefits of using CloudFront - many of which aligned perfectly with our objectives for the website redesign. One of the absolute best benefits of using CloudFront is it completely eliminates the need for you to manage any of your own servers. This approach can result in dramatic operational simplifications, cost savings, and enhanced security. No more applying server patches or wasted compute cycles. We were ready to start using the same serverless technology that we had been using on customer projects on our own website in our own environment.
The overarching design strategy and rollout plan was simple: iterate on the website using local development environments (Macbooks) until the website was ready for the deployment step which was a simple DNS cut-over. With that plan in place, we got to work with our user centered design and UX process that we will describe in another article. We decided to use gatsbyjs with ReactJS to create the project structure for the static content.
The underlying AWS infrastructure components for the website are shown below in Figure 3. As illustrated in the figure, we used a single CloudFront distribution with a S3 bucket "origin" containing the static resources comprising the website. Any request made to bridgephase.com is resolved by the AWS Route53 DNS server to the lowest latency CloudFront edge location as determined by AWS based on, primarily, the geographical location from which the request originated. So someone in California would have requests for the website routed to a completely different, and much closer, edge location than the edge location used to serve content to someone in Washington DC. The edge locations allow us to achieve a specific objective which was to provide consistent performance throughout the continental United States.
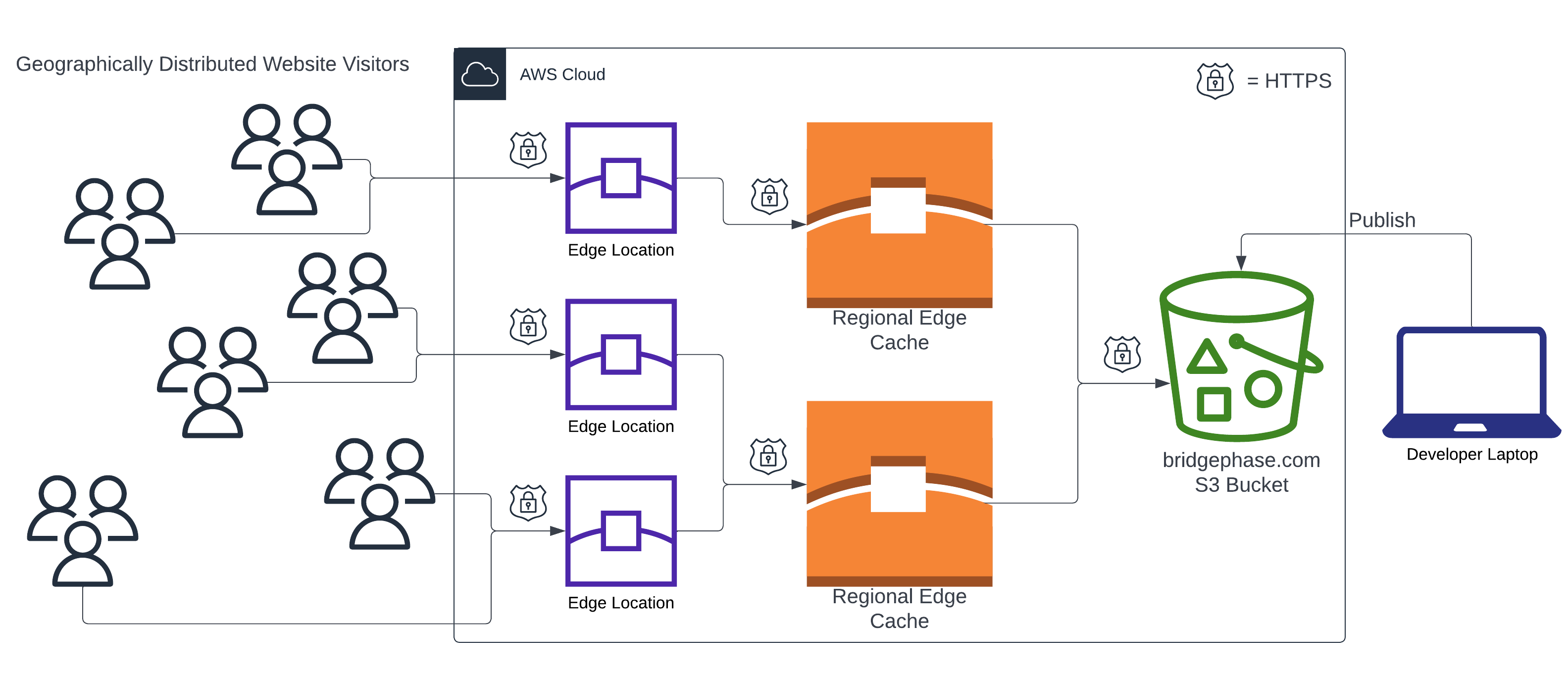
After a few weeks of iterating on the website design locally, we were ready to roll it out using CloudFront. We used some in-house Terraform modules to provision the S3 bucket, CloudFront distribution, ACM certificate (for HTTPS), and security policies/rules. Once the static website bundle (the code) was uploaded to the S3 bucket and we verified that the website was accessible via the CloudFront distribution, we then cutover the bridgephase.com DNS entry which had been pointing to the Elastic IP address associated with the Wordpress EC2 instance to the CloudFront distribution. Everything worked perfectly!
Improvements
With the website deployed using the new serverless architecture, it was time to assess whether we had been successful in meeting the objectives that we defined at the start of the redesign. Let's take a look at each objective to see how we did.
- ✅ Security - All traffic is encrypted via HTTPS with TLS version 1.2 or higher enforced. If you attempt to access the website via plain http (e.g. http://bridgephase.com), your request will automatically be upgraded via redirection to a secure HTTPS connection. The security policies in place on the CloudFront distribution and S3 bucket lock them down such that external access or configuration changes are blocked. Additionally, we applied a geographical "whitelist" to the CloudFront distribution. Since BridgePhase primarily serves the US federal government, the website only accepts requests from IP addresses in the US and Canada.
- ✅ Availability - Our website now inherits the SLAs of AWS CloudFront and S3 - which both have a 99.9% SLA. Both CloudFront and S3 are fault tolerant. An outage or service disruption within a single availability zone will not affect the availability of the website.
- ✅ Performance - Our website has a PageSpeed score of 88 at the time of writing this article. That performance score is consistent throughout the continental United States thanks to the distributed edge locations provided by CloudFront.
- ✅ Maintenance & Operations - Our website is now completely serverless! The only ongoing maintenance is updates to the website content itself.
- ✅ Open Source - A completely open source tech stack was used to develop the website. As we mentioned above, GatsbyJS and ReactJS were used in conjunction with HTML and CSS.
The last objective was reducing cloud spend related to operating the website. Let's look at how we met this final objective in more detail.
Cost Effectiveness - FinOps
As cloud adoption continues to proliferate and organizations move more workloads to cloud providers like AWS, many business and IT leaders find themselves struggling to get a handle on spiraling costs incurred on cloud based resources - a.k.a. "cloud spend". A deep understanding of a cloud provider's pricing structure, the service offerings, APIs, and billing tools are need to conduct proper financial operations (FinOps) within a given cloud environment. We've been helping our customers make sense of their cloud spend and reduce operational costs relative to the size of their cloud based workloads. Let's use the BridgePhase website as an example with all services deployed in the us-east-1/N.Virginia region.
- Compute:
- EC2 Instance: An on-demand t3.small EC2 instance costs $0.0208 per hour. The server was running 24 hours per day to host our website. The monthly cost works out to around $15 assuming 30 days in a typical month ($0.0208 x 24 x 30).
- RDS MySQL Instance: A db.t3.small RDS MySQL Instance costs $0.034 per hour. The instance was running 24 hours per day as the persistent store for Wordpress. The monthly cost works to $24.48 for a typical month.
- Network:
- Managed NAT Gateway: This service, which is used to perform NAT between private subnets and the internet, costs $0.045/HR and $0.045/GB of data processed. Assuming 24 hours per day, 30 days per month, and 5 GB of data transfer, the monthly cost is about $33 per month.
- Storage:
- EBS Volume: A single General Purpose SSD (gp3) EBS volume costs $0.08/GB-month. At 20GB of storage, the monthly cost is $1.60.
- RDS Storage: MySQL RDS storage costs $0.115 per GB-month. At 10GB of storage, the monthly cost is $1.15.
So the total monthly cost of the Wordpress version of the website was $15 + $24.50 + $33 + $1.60 + $1.15 = $75.25.
Now let's look at our serverless deployment with CloudFront.
- Compute: None! We are completely serverless!
- Network:
- CloudFront Data Transfer - 1 TB of data transfer out and 10,000,000 HTTP/HTTPS Requests per month is always free. Our requests and data transfer are much, much lower than those thresholds so CloudFront costs us nothing.
- S3 Data Transfer - Standard tier HTTP/HTTPS requests cost $0.005 for 1,000 for POST requests AND $0.004 for 1,000 GET requests. We will use the higher unit price of $0.005 for all requests to be conservative. Since CloudFront caches content at edge locations and regional caches, only a small number of requests to bridgephase.com result in requests to S3 to fetch static content. As a VERY conservative estimate, let's say our S3 bucket receives 1, 000 requests per day which is about 30,000 requests per month. Those requests incur $0.15 of costs. The first 100GB per month of data transfer out to the internet from S3 is free. So the total cost network cost for S3 is that $0.15 per month.
- Storage:
- S3 Bucket - Standard tier storage costs $0.023 per GB for up to 50TB. Our website content is currently less than 1GB but to be conservative we will round up and say that we spend $0.03 per month on storage.
The total monthly cost of our serverless website deployment is only 18 cents. That's a cost savings of $75.07 per month and an amazing 99% reduction in cloud spend!
Closing Remarks
Depending on your workloads and organization needs, serverless solutions can provide exceptional value and flexibility. Moving the BridgePhase website to serverless infrastructure has proven to be one of the best architectural changes that we've ever made. So the next time your organization takes on a new initiative or a fresh look at objectives, consider asking - "Should we go serverless?".
Thanks for reading!
Topics in this article: