
AI Cost Compression: Using Quantization to Scale AI Efficiently
Topics in this article:
Conversations about AI, especially large language models (LLMs), tend to focus on capabilities such as reasoning and code generation. While model capabilities have improved significantly, unlocking new use cases and applications, the costs associated with running these models and performing inference at scale can be prohibitive. To reduce costs, many organizations are exploring options for increasing inference efficiency while maintaining quality and performance.
One highly effective technique that can help drive efficiency is quantization. Quantization is the process of reducing the numerical precision used to represent model weights. AI models such as LLMs are pretrained (GPT = Generative Pretrained Transformer). The training process is used to calculate weights. In transformer-based architectures and models based on neural networks, weights are not just a single list of numbers. They are organized into specific weight matrices located within the layers of the model. Quantization is applied to adjust the numerical precision of the numbers inside these matrices such that less memory is required to load and store the weights.
In plain terms, quantization can be considered a form of compression. It is one of the most practical ways to reduce memory pressure and improve throughput on modern hardware. In business terms, it can materially influence cost and capacity planning.
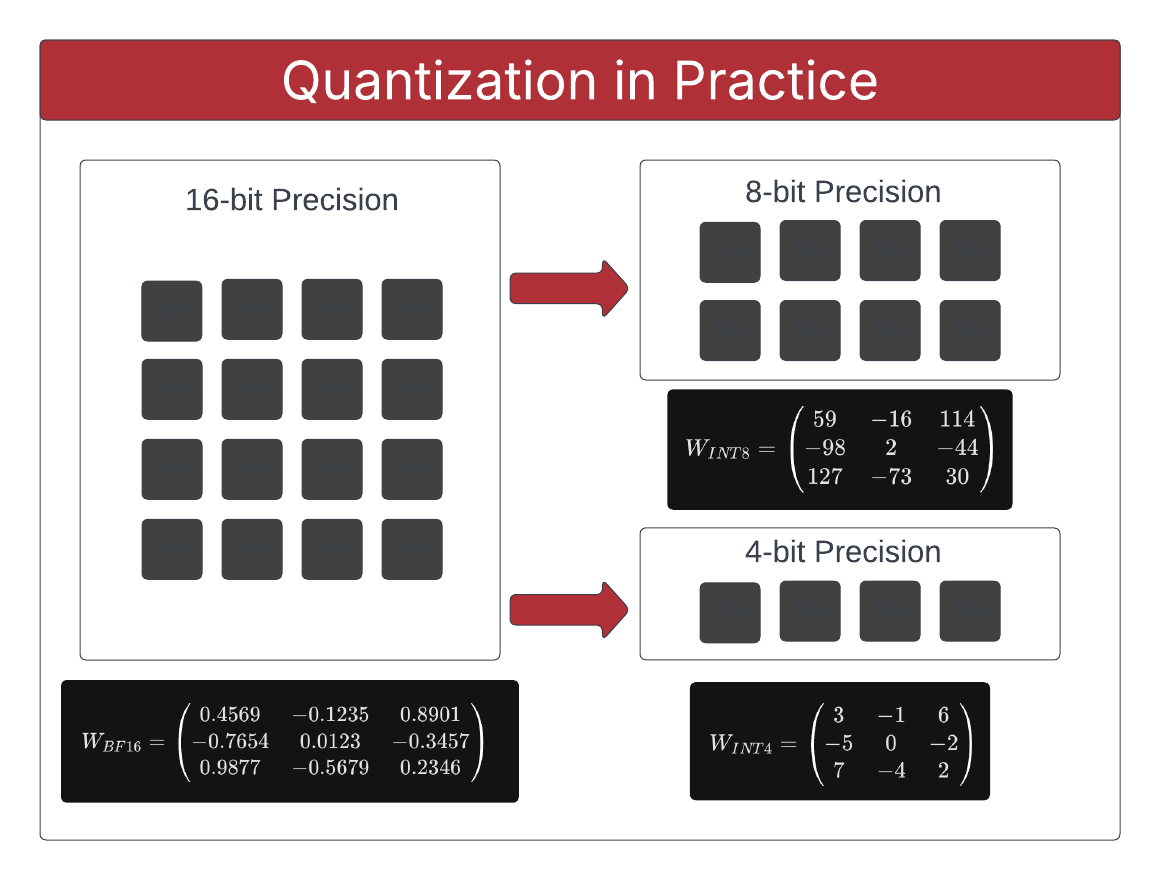
As with any form of compression, quantization creates a tradeoff between accuracy and efficiency. We decided to explore that tradeoff using benchmarks to evaluate real data generated in the BridgePhase lab environment. This write-up captures what we built, what we learned, and why this work matters for business stakeholders and engineering teams alike.
The purpose of this benchmarking effort was to explore the effects of quantization in a practical, repeatable way so we could better understand the tradeoffs between model quality and resource utilization at different precision levels. Specifically, we wanted to evaluate what is gained and what is lost when moving from standard 16-bit precision floating point weights (BF16) to lower precision weights expressed as integers (INT8 and INT4). By understanding the tradeoffs, we can make concrete recommendations that influence architecture and cost decisions in enterprise environments.
Approach
To evaluate quantization, we measured quality metrics on representative evaluation tasks and performance metrics including throughput, latency, and GPU memory (VRAM) usage.
The goal was not to prove that one precision mode is universally best. The goal was to make the tradeoffs visible. A modest quality drop might be acceptable for one class of requests if it enables materially lower memory use and better throughput. The same quality drop might be unacceptable for another class of requests where precision and consistency are critical.
That distinction is important because model serving decisions are rarely made in a vacuum. They are made in the context of user experience targets, infrastructure budgets, and peak demand behavior. Quantization gives teams more levers, but those levers need evidence-based guardrails.
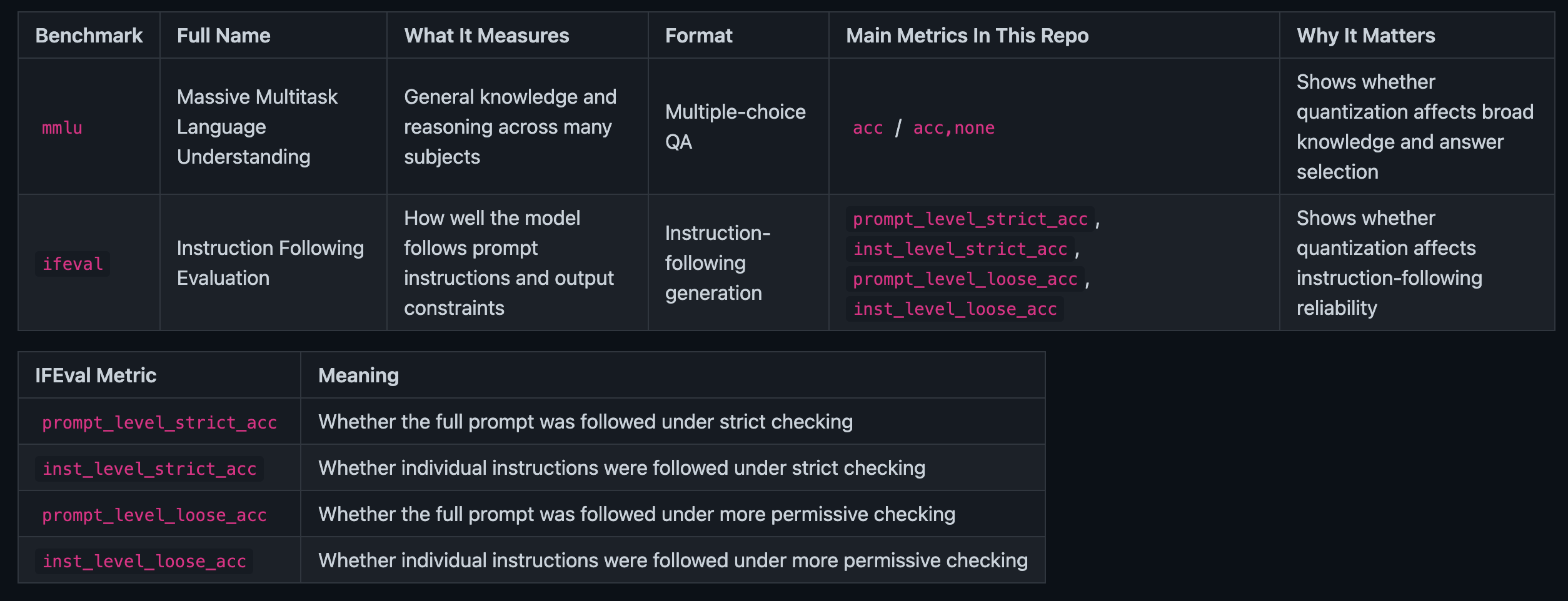
To generate data and perform an evidence-based comparison, we used specific benchmarks from LM Evaluation Harness, which is a benchmarking framework that provides a standardized way to evaluate LLMs. While the framework provides dozens of possible evaluation tasks, we focused on Massive Multitask Language Understanding (mmlu) and Instruction Following Evaluation (ifeval) to balance time required for evaluation and representative use cases. A detailed overview of the benchmark tasks is provided in the table below.
Benchmark runs were executed sequentially on a single AWS EC2 g5.2xlarge instance with an NVIDIA A10G GPU and the following hardware specifications:

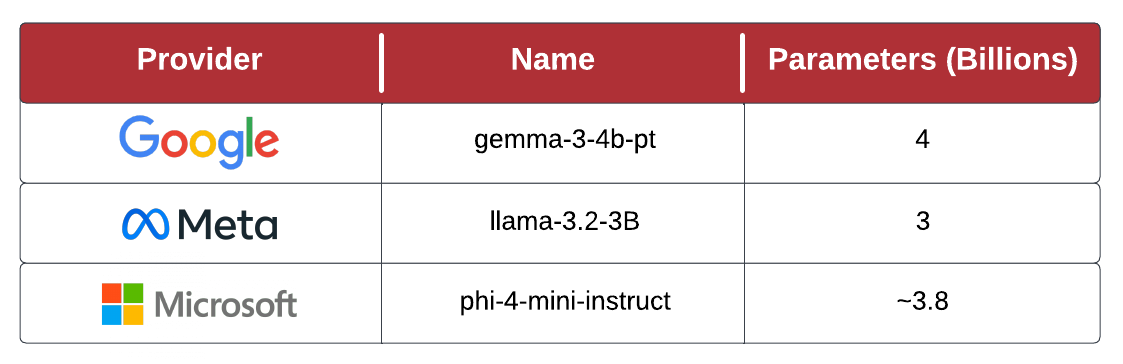
When selecting models for evaluation, we focused on quantization-friendly architectures, US provenance, and size (parameters). We wanted models large enough to be powerful and useful but small enough to fit in a single GPU on a reasonably sized EC2 instance. The selected models, shown below, are all available on Hugging Face's model hub.
With the infrastructure in place, the models selected, and the benchmark tasks defined, we proceeded to create automated scaffolding to orchestrate the evaluation. The code created for this orchestration, along with raw results files, are available on GitHub.
It's important to note that quantization is a broad topic and there are many different ways to implement it. The particular type of quantization used for this analysis is called Post-Training Quantization (PTQ). For a more in-depth explanation of quantization, numeric precision, and state-of-the-art techniques for quantizing models, see this thorough reference.
Results
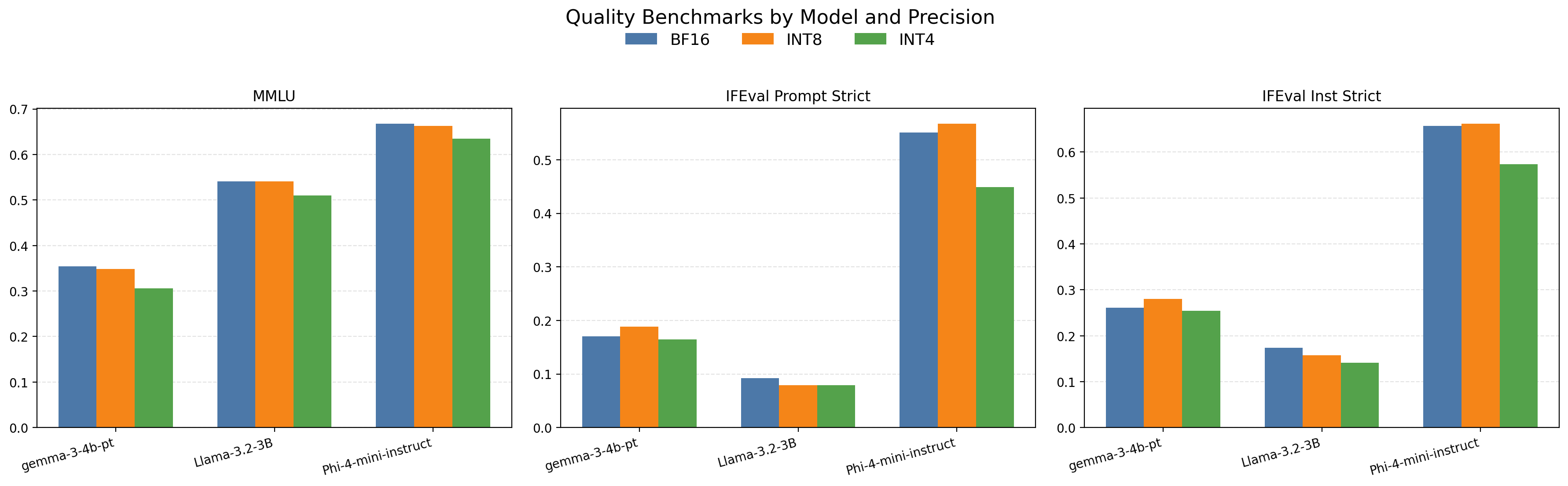
Let's take a look at the results starting with the quality metrics shown in Figure 6. By examining these results, two things are immediately apparent:
- 1. Size Isn't the Most Important Factor - The 4B parameter Gemma model performs significanlty worse than the 3.8B parameter Phi model on all quality benchmarks. The smaller, 3.2B parameter Llama model also scored better on MMLU than the 4B parameter Gemma model.
- 2. 8-Bit Quantization Parity - Models quantized at 8-bit precision demonstrate comparable quality performance to full precision models. Note that in some of the graphs 8-bit quantization appears to outperform full precision but small differences are expected due to randomization in sample generation. With that understanding, it's clear that 8-bit quantization sacrifices a small amount of quality, whereas quality drops significantly for 4-bit quantization.
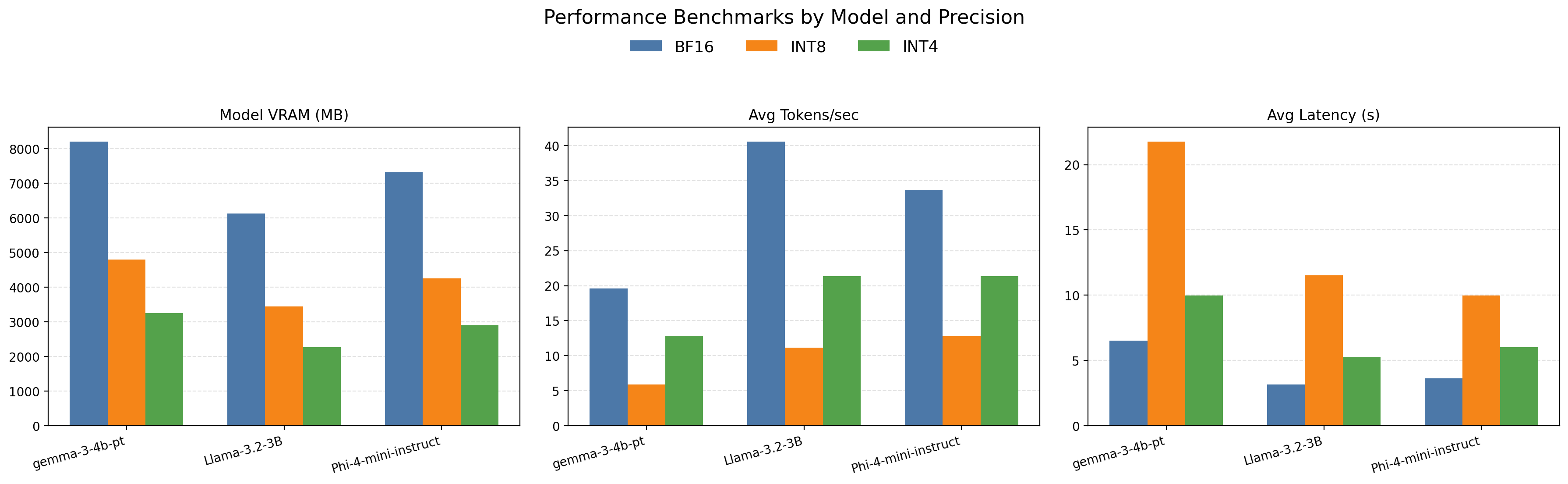
The performance metrics shown in Figure 7 are more striking. Quantized models reduce GPU memory consumption substantially but there appears to be diminishing returns at the lower 4-bit precision level. This is likely due to memory overhead in the bitsandbytes quantization library at 4-bit precision. Throughput and latency are generally better at the default 16-bit precision. There appears to be some unexpected variation in throughput and latency at the 8-bit precision level as well. This is, again, likely due to the quantization library being optimized for certain kernel configurations and precision levels.
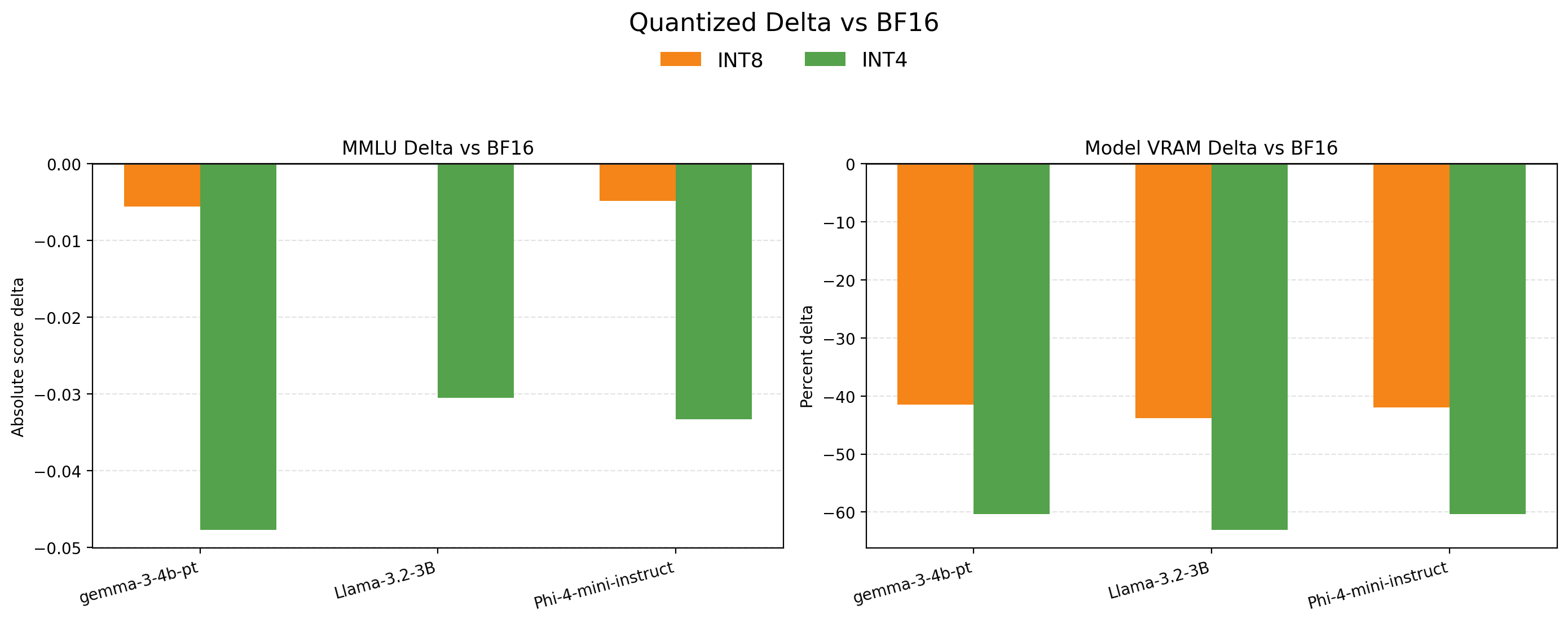
Directly comparing relative quality differences with memory consumption clearly illustrates the tradeoffs. 8-bit quantization has a negligible impact on quality while achieving a 40%+ reduction in memory consumption. 4-bit quantization reduces memory consumption by 60% but has significant quality degradation.
Initial Takeaway
The central insight is straightforward:
- Quantization can unlock significant memory and cost advantages.
- The quality impact is workload-dependent and must be measured, not assumed.
- The right answer is rarely one static precision mode for all traffic.
A more realistic production posture is policy-based serving using precision tiers based on workload criticality, latency targets, and real-time capacity conditions. It is reasonable to suspect that major consumer AI chat applications (ChatGPT, Gemini, Claude, and peers) already use some form of quantization-aware routing in production, particularly during peak demand windows.
The economics strongly support the idea. If demand spikes and you need to preserve responsiveness while controlling compute costs, delegating some traffic to quantized model paths is a rational strategy, assuming quality remains within acceptable bounds for that request class.
Business Implications
For AI-enabled products, quantization is not just a model optimization detail. It is potentially a margin and reliability lever. At a high level:
- Higher precision (BF16) generally preserves quality but consumes more memory.
- Lower precision (INT8/INT4) can reduce memory footprint significantly and often improve throughput.
- The tradeoff is that aggressive quantization may degrade task quality depending on model and task pairings.
- 8-bit quantization appears to be a good compromise between quality and memory for the benchmarks we tested.
That precision versus memory tradeoff can cascade into business outcomes:
- Infrastructure Cost: lower memory per model can increase model density per GPU.
- Capacity Under Load: better throughput can help absorb peak traffic without linear hardware growth.
- Latency Targets: some workloads see meaningful latency gains with lower-bit inference.
- Quality Risk: if quantization impacts core product quality metrics, savings may not be worth it.
Lower GPU memory per model is often expressed in terms of GPU density. Higher GPU density directly translates into cost savings by enabling more models to fit within the memory of a single GPU. In our simple benchmarking exercise, we used a single instance with a single GPU. It's common for enterprise environments to run hundreds or thousands of instances with multiple models deployed to each instance sharing either a single GPU on the instance or consuming a dedicated GPU on a multi-GPU instance. In those types of environments, GPU density is a critical FinOps control. A summary of how quantization impacts GPU density and estimated annual cost savings for a single g5.2xlarge instance are provided below.
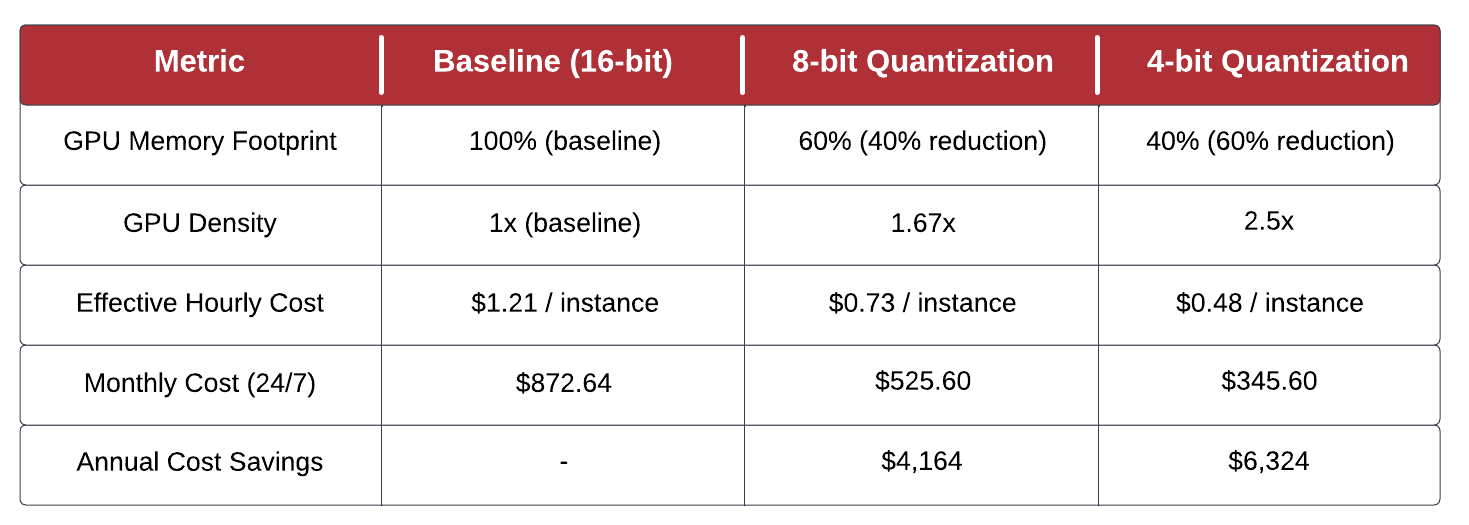
Based on the estimated cost savings for a single instance, an enterprise environment running even a modest number of instances could potentially save hundreds of thousands of dollars annually through quantization.
In other words, quantization is not simply faster and cheaper. It is a controlled optimization problem with business
constraints, customer expectations, and operational realities. At BridgePhase, those are exactly the types of problems that we help solve for our customers.
Conclusion
Quantization is one of the clearest examples of technical optimization intersecting with business outcomes.
If your organization is deploying AI-powered capabilities, the question is not whether quantization is good or bad. The better question is where each precision tier creates the most value for your users and your operating model.
Topics in this article: